How to Make a Wordcloud Using R
Recently I have been using R for some basic data visualisations, outputs like word clouds and heat maps. I don't have a programming background so upon first look the R command line based environment can seem a little daunting. However, the ease at which I have been able to create some pretty amazing outputs with very little code has surprised me. In this blog I will attempt to share the steps in a simple process as well as the small amount of code that is needed.
1. RStudio + Packages #
First of all, you will need to install RStudio. The program gives the user a nice interface to operate within. The code can be typed in the window to the top left of the program, useful particularly if you want to save your code as a script. The code can be sent to the command line from there, or you can simply start typing the code into the Console.
# Install required packages
install.packages(c("tm", "wordcloud","SnowballC"))
# Load libraries
library(tm)
library(wordcloud)
library(SnowballC)2. Load the Text #
This is the point where you load the text with which you would like to create your word cloud with. For this example I am using JFK's 'We choose to go to the Moon' speech.
Create a new folder e.g. ~/Desktop/test/ containing a speech.txt file.
# Create a corpus variable
mooncloud <- Corpus(DirSource("~/Desktop/test/"))
# Make sure it has loaded properly - have a look!
inspect(mooncloud)3. Format and Clean the Text #
These commands will remove various things like punctuations and english words you aren't particularly interested in for the cloud like conjunctions. Additionally it will format the case of the text, I am going to go with lowercase, however you can run various combinations of these arguments including arguments not listed here.
# Strip unnecessary whitespace
mooncloud <- tm_map(mooncloud, stripWhitespace)
# Convert to lowercase
mooncloud <- tm_map(mooncloud, tolower)
# Remove conjunctions etc.
mooncloud <- tm_map(mooncloud, removeWords, stopwords("english"))
# Remove suffixes to the common 'stem'
mooncloud <- tm_map(mooncloud, stemDocument)
# Remove commas etc.
mooncloud <- tm_map(mooncloud, removePunctuation)
#(optional) arguments of 'tm' are converting the document to something other than text, to avoid, run this line
mooncloud <- tm_map(mooncloud, PlainTextDocument)4. Word Cloud Time! #
Time to produce a word cloud, run the following command and watch RStudio populate the 'Plots' window to the right of the console.
# Time to generate a wordcloud!
wordcloud(mooncloud
, scale=c(5,0.5) # Set min and max scale
, max.words=100 # Set top n words
, random.order=FALSE # Words in decreasing freq
, rot.per=0.35 # % of vertical words
, use.r.layout=FALSE # Use C++ collision detection
, colors=brewer.pal(8, "Dark2"))5. The Result #
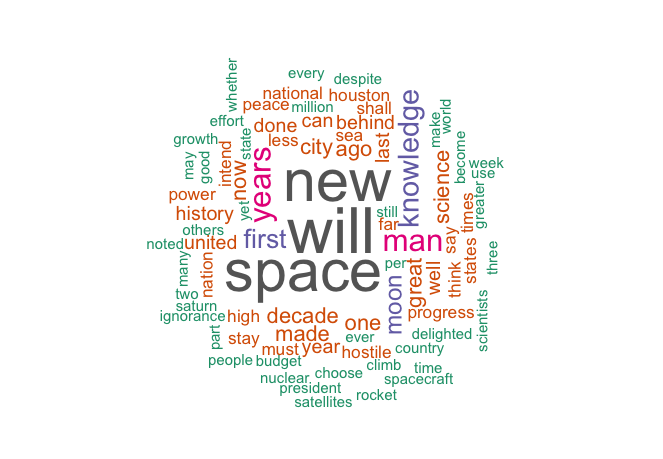
Voilà! Where there is a 'will' there is a way. It's hard to imagine a current leader of a western country announcing such a bold and expensive policy now - despite the world increasing its wealth substantially in the last half century of rapid development and therefore being even more capable than it was in the 60s.
Back to technical aspects, for further information and optional arguments you can use to customise the word cloud please see the following:
- tm - the text mining package
- wordcloud - the cloud generator, also does commonality clouds e.g. compare two political speeches for common themes
- SnowballC - multi-language stemming algorithm package
I learnt to do this from a fair amount of Googling. The most helpful blog I came across was Georeferenced - so credit where credit is due. I learnt this method due to Wordle being blocked from my workplace, so of course use the website if you want to keep your hands clean!
✍️ Want to suggest an edit? Raise a PR or an issue on Github